What is an AI data analyst?
Explore how generative AI is reshaping analytics, intriguing professionals with its potential while signaling automation's impact on data analysis roles.
Chris Stanley
·
April 22, 2024
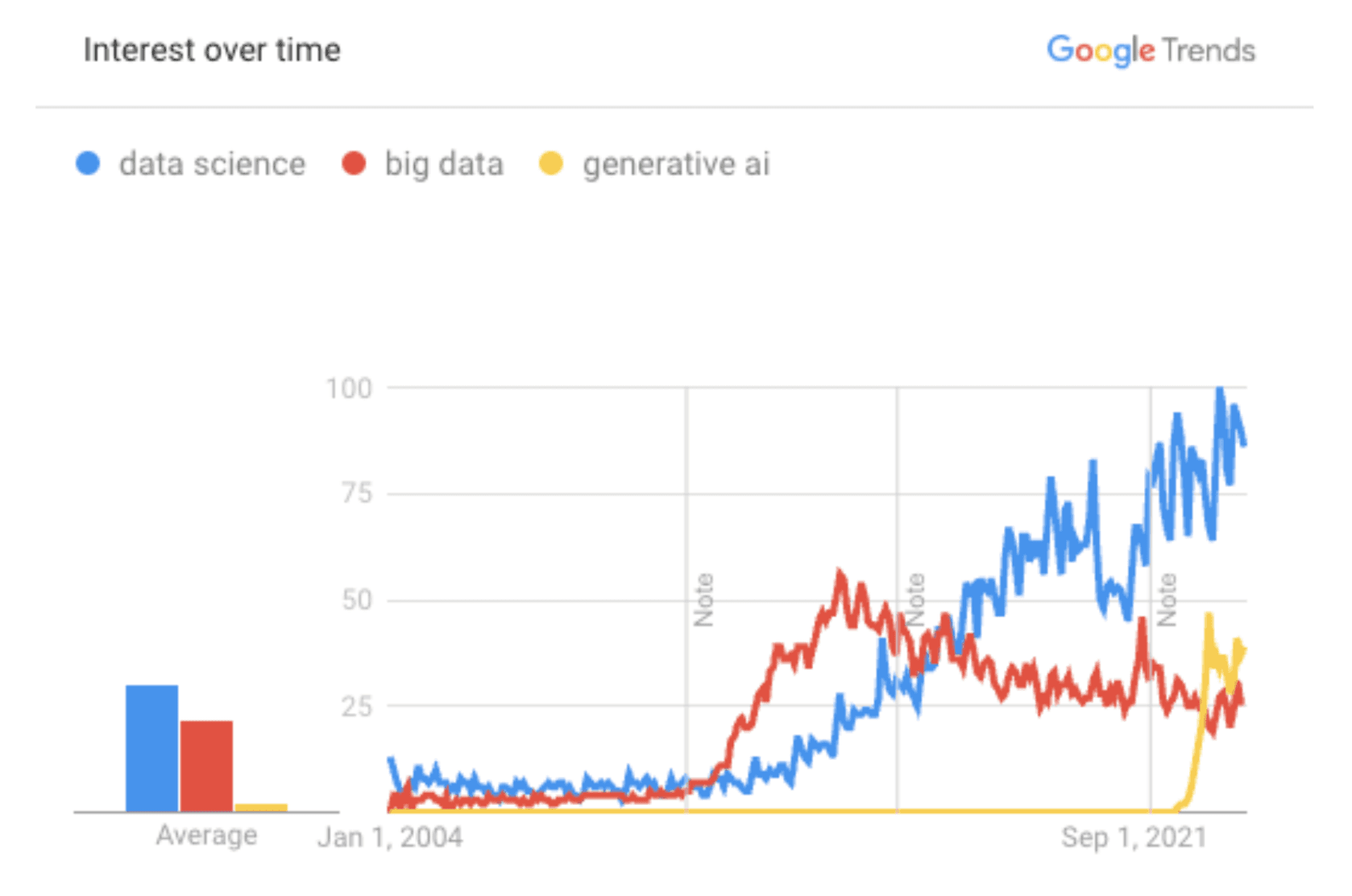
With the emergence of generative AI, analytics professionals have met the technology with intrigue and unease. It has forced a paradigm shift in what data analysts do. Curious data analysts are leveraging these tools to augment their work, while others may be seeing the writing on the wall, and to them, it reads “automate and replace.”
The concept of an “AI data analyst” has emerged to address both cases. For the former, the title has been used to describe data analysts who “combine traditional data analyst skills with expertise in AI and machine learning.” For the latter, it’s been used to describe the machine that replaces this role.
The future of data analysts might be somewhere in the middle. As this technology matures, so do its use cases. And it's those use cases that will shape what analytics looks like in the years to come.
An Etymology of the Four Types of Analytics
To understand how generative AI impacts data analysts and where this may be going, we must understand what analytics looks like today and where these roles currently operate.
Most analytics professionals work within four types of analytics: descriptive, diagnostic, predictive, and prescriptive. We can think of them as a pyramid built on top of one another, even though the roles and the types of analyses done within each layer can influence and impact another:
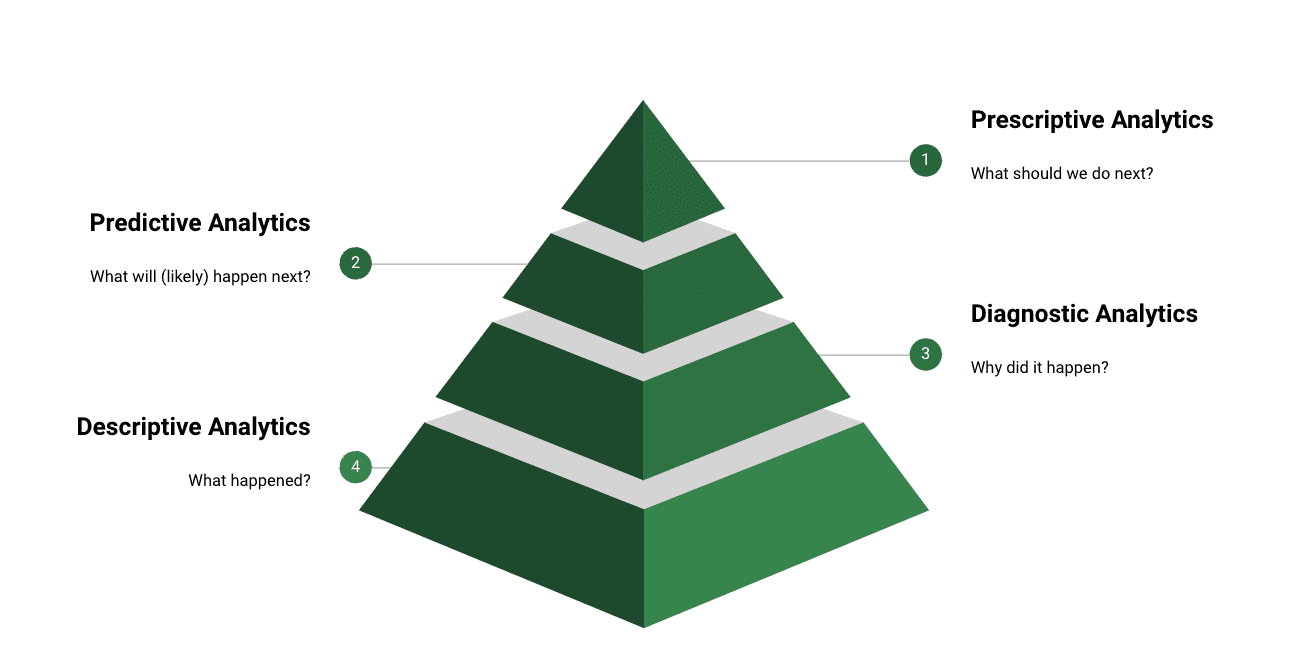
The most basic but foundational type of analytics is descriptive analytics. Harvard Business School describes descriptive analytics as “the process of using current and historical data to identify trends.” Descriptive analytics answers the question “what happened?” through analyses like looking at medians and means or charting data over time to see trends.
Diagnostic analytics is built on top of descriptive analytics. This type of analysis asks why something happened. Common techniques include hypothesis testing or looking at correlation and basic regression to help understand what’s driving a given result.
We do so much more with analytics today, and the significant difference between a data analyst and a data scientist comes when we jump from diagnostic to predictive analytics. IBM describes predictive analytics as the ability “to make predictions about future outcomes using historical data combined with statistical modeling, data mining techniques, and machine learning.” This builds on what we know from descriptive analyses and why we think it’s happening via diagnostic analyses to inform models like classification or clustering to anticipate what comes next.
Prescriptive analytics is the newest type to emerge and, as a result, is the hardest to define. Davide Frazzetto, Thomas Dyhre Nielsen, Torben Bach Pedersen, and Laurynas Siksnys, in their paper “Prescriptive Analytics: A Survey of Emerging Trends and Technologies,” describe prescriptive analytics as what “fills the gap between data and decisions.” They point to how prescriptive analytics takes the work from predictive analytics and uses those models to make decisions. That then is fed back to predictive analytics to reinforce models and decision-making. A good example of prescriptive analytics is how Google Maps takes in traffic data to help plan routes.
Where did Data Analysts and Data Scientists Come From?
Data analysts have worked in descriptive and diagnostic analytics for as long as computation has existed. Most of the work in these two spaces is based on foundational statistical concepts like mean, median, standard deviation, and the like. These concepts were sufficient for the amount of data we were collecting back then.
Then came “big data” and the data scientists trained to study it.
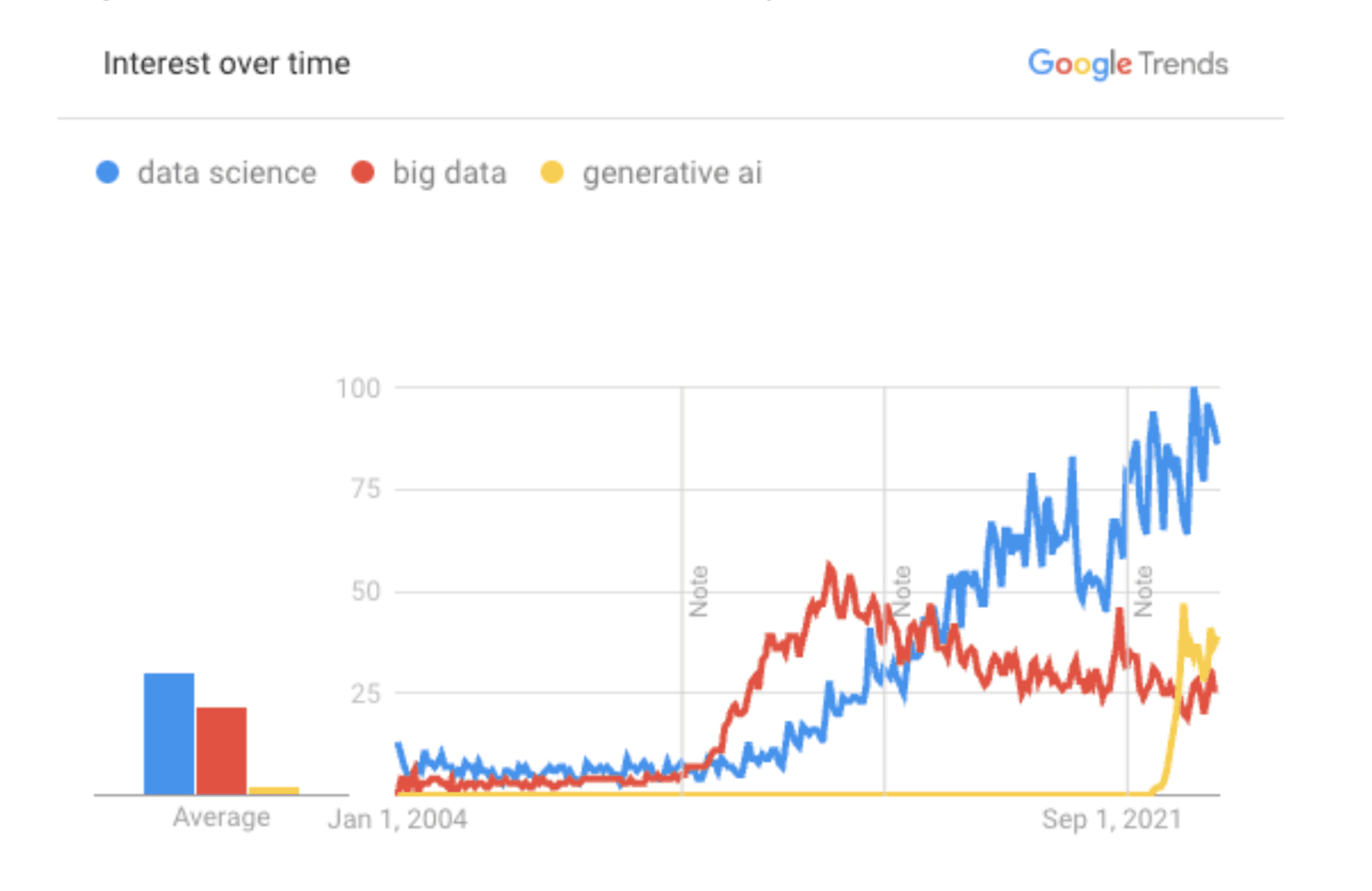
While Google trends indicated a rise in big data in the 2010s, the concept of big data came much earlier. In the late 1990s, computer scientists like John Mashey were looking to describe what they saw emerging in Silicon Valley: the different waves of more data sources, cheaper storage, and better computational power all cresting at once. Descriptive and diagnostic analytics could start to make sense of this new ocean of data, but we would need better techniques to understand the “why” and to move into predictive techniques.
The field of data science was almost exclusively academic at this point. Many credit Peter Naur for creating the term in 1974, when he started to draw the lines between data as a concept and what fields we would need to understand it better. Back then, prediction wasn’t even part of it. Data science and the idea of a data scientist didn’t take off until the 2010s when that big data wave was inundating most industries.
For the most part, data scientists tended to pick up where data analysts left off. Predictive techniques like regression models, decision trees, and neural networks require the foundation of descriptive and diagnostic analytics to predict.
As data science matured, the concept of prescriptive analytics started to emerge. Atanu Basu described the concept in 2019 as “practical and timely action plans to take advantage of the predictions” coming out of these models. It was natural for data science to take this branch of analytics.
The lines started to become clear: data analysts’ domain was in descriptive and diagnostic analytics, and data scientists would focus on making predictive and prescriptive models. This became the structure of a typical analytical organization.
“Human in the Loop” Instead of AI-First
Then came generative AI to blur those lines. And it didn’t take long.
It seemed like overnight tools like ChatGPT and Copilot became essential working companions. They continue to be force multipliers in the workplace, no matter the field or the role.
It is also natural for a data analyst to assume that generative AI is coming for jobs. Generative AI can be trained on internal data and documents, allowing it to do a decent chunk of diagnostic analytics. It already performs well with descriptive data if the datasets are processed cleanly. No wonder students in the field ask if they’ve chosen an “obsolete” career path, anticipating a future where AI data analysts are embedded in organizations instead.
Data scientists are not off the hook, either. While their domain transitions nicely to training and maintaining these large language models, much of the work needed to maintain these models occur in earlier analytical stages like predictive and prescriptive analytics.
So, what does a data analyst do? Should they simply concede to the future of automation? Find another job? Before hitting the panic button, we should recognize that this problem is not new. People are already thinking about structural shifts in how we can integrate generative AI without automating our jobs.
One of the concepts at the forefront of this human versus AI problem is the idea of a “human in the loop.” This concept emphasizes the importance of human expertise and judgment in the AI-driven analytics process. Stanford University’s Institute for Human-Centered AI frames this idea around a simple question: “How do we incorporate useful, meaningful human interaction into the system?”
For a data analyst with that panic button half-pressed already, it’s going to take a process of reframing what a data analyst can do when letting these tools enable their work. For instance, generative AI can help produce more accurate and efficient analyses by automating repetitive tasks like data processing and exploratory data analysis.
This integration of generative AI into data analysts' and data scientists' roles can bring significant benefits. It can allow data analysts to take on more predictive and even prescriptive analytics tasks, working closer with their data science peers. It can enable data analysts to spend more time on human-centric problems. The data analyst can spend more time asking “why” instead of “what happened” and then continue up the pyramid to understand what happens next and what they should do about it.
How do I become an AI Data Analyst?
Integrating generative AI into an analyst’s workflow should be done judiciously. Are you aiming to enhance your productivity, or do you seek to develop a tool that your colleagues can use, potentially reducing the number of dashboard requests you handle? For those interested in AI assistants that improve workflow efficiency, consider exploring options like Tableau Pulse or Copilot on PowerBI.
If your goal is to provide non-technical users with tools that enable them to perform their analyses, thus reducing the number of data and dashboard requests that accumulate in your queue, you might want to explore a solution like Patterns.
Tools need a problem to solve, though. A data analyst should ask questions about their work to see where these tools fit best. Here are some examples:
What tasks can I automate using generative AI?
Where is human judgment needed in my workflow?
What insights can I improve on or check using generative AI?
How much time does generative AI save me? And what will I do with that time instead?
Where in my organization can I utilize generative AI to disseminate analyses?
What infrastructure is in place to support this? What data privacy considerations do I need to make?
Stanford stresses that to make the “human in the loop” concept work, these tools “should extend us.” Using these tools as an extension of a data analyst’s work will enable you to tackle those new and exciting problems, and enhance the work data analysts are already tasked with today. It should also guarantee that the AI data analysts of the future can reap the benefits of generative AI without worrying about replacement.
Analytics in natural language
What is an AI data analyst?
Explore how generative AI is reshaping analytics, intriguing professionals with its potential while signaling automation's impact on data analysis roles.
Chris Stanley
·
April 22, 2024
With the emergence of generative AI, analytics professionals have met the technology with intrigue and unease. It has forced a paradigm shift in what data analysts do. Curious data analysts are leveraging these tools to augment their work, while others may be seeing the writing on the wall, and to them, it reads “automate and replace.”
The concept of an “AI data analyst” has emerged to address both cases. For the former, the title has been used to describe data analysts who “combine traditional data analyst skills with expertise in AI and machine learning.” For the latter, it’s been used to describe the machine that replaces this role.
The future of data analysts might be somewhere in the middle. As this technology matures, so do its use cases. And it's those use cases that will shape what analytics looks like in the years to come.
An Etymology of the Four Types of Analytics
To understand how generative AI impacts data analysts and where this may be going, we must understand what analytics looks like today and where these roles currently operate.
Most analytics professionals work within four types of analytics: descriptive, diagnostic, predictive, and prescriptive. We can think of them as a pyramid built on top of one another, even though the roles and the types of analyses done within each layer can influence and impact another:
The most basic but foundational type of analytics is descriptive analytics. Harvard Business School describes descriptive analytics as “the process of using current and historical data to identify trends.” Descriptive analytics answers the question “what happened?” through analyses like looking at medians and means or charting data over time to see trends.
Diagnostic analytics is built on top of descriptive analytics. This type of analysis asks why something happened. Common techniques include hypothesis testing or looking at correlation and basic regression to help understand what’s driving a given result.
We do so much more with analytics today, and the significant difference between a data analyst and a data scientist comes when we jump from diagnostic to predictive analytics. IBM describes predictive analytics as the ability “to make predictions about future outcomes using historical data combined with statistical modeling, data mining techniques, and machine learning.” This builds on what we know from descriptive analyses and why we think it’s happening via diagnostic analyses to inform models like classification or clustering to anticipate what comes next.
Prescriptive analytics is the newest type to emerge and, as a result, is the hardest to define. Davide Frazzetto, Thomas Dyhre Nielsen, Torben Bach Pedersen, and Laurynas Siksnys, in their paper “Prescriptive Analytics: A Survey of Emerging Trends and Technologies,” describe prescriptive analytics as what “fills the gap between data and decisions.” They point to how prescriptive analytics takes the work from predictive analytics and uses those models to make decisions. That then is fed back to predictive analytics to reinforce models and decision-making. A good example of prescriptive analytics is how Google Maps takes in traffic data to help plan routes.
Where did Data Analysts and Data Scientists Come From?
Data analysts have worked in descriptive and diagnostic analytics for as long as computation has existed. Most of the work in these two spaces is based on foundational statistical concepts like mean, median, standard deviation, and the like. These concepts were sufficient for the amount of data we were collecting back then.
Then came “big data” and the data scientists trained to study it.
While Google trends indicated a rise in big data in the 2010s, the concept of big data came much earlier. In the late 1990s, computer scientists like John Mashey were looking to describe what they saw emerging in Silicon Valley: the different waves of more data sources, cheaper storage, and better computational power all cresting at once. Descriptive and diagnostic analytics could start to make sense of this new ocean of data, but we would need better techniques to understand the “why” and to move into predictive techniques.
The field of data science was almost exclusively academic at this point. Many credit Peter Naur for creating the term in 1974, when he started to draw the lines between data as a concept and what fields we would need to understand it better. Back then, prediction wasn’t even part of it. Data science and the idea of a data scientist didn’t take off until the 2010s when that big data wave was inundating most industries.
For the most part, data scientists tended to pick up where data analysts left off. Predictive techniques like regression models, decision trees, and neural networks require the foundation of descriptive and diagnostic analytics to predict.
As data science matured, the concept of prescriptive analytics started to emerge. Atanu Basu described the concept in 2019 as “practical and timely action plans to take advantage of the predictions” coming out of these models. It was natural for data science to take this branch of analytics.
The lines started to become clear: data analysts’ domain was in descriptive and diagnostic analytics, and data scientists would focus on making predictive and prescriptive models. This became the structure of a typical analytical organization.
“Human in the Loop” Instead of AI-First
Then came generative AI to blur those lines. And it didn’t take long.
It seemed like overnight tools like ChatGPT and Copilot became essential working companions. They continue to be force multipliers in the workplace, no matter the field or the role.
It is also natural for a data analyst to assume that generative AI is coming for jobs. Generative AI can be trained on internal data and documents, allowing it to do a decent chunk of diagnostic analytics. It already performs well with descriptive data if the datasets are processed cleanly. No wonder students in the field ask if they’ve chosen an “obsolete” career path, anticipating a future where AI data analysts are embedded in organizations instead.
Data scientists are not off the hook, either. While their domain transitions nicely to training and maintaining these large language models, much of the work needed to maintain these models occur in earlier analytical stages like predictive and prescriptive analytics.
So, what does a data analyst do? Should they simply concede to the future of automation? Find another job? Before hitting the panic button, we should recognize that this problem is not new. People are already thinking about structural shifts in how we can integrate generative AI without automating our jobs.
One of the concepts at the forefront of this human versus AI problem is the idea of a “human in the loop.” This concept emphasizes the importance of human expertise and judgment in the AI-driven analytics process. Stanford University’s Institute for Human-Centered AI frames this idea around a simple question: “How do we incorporate useful, meaningful human interaction into the system?”
For a data analyst with that panic button half-pressed already, it’s going to take a process of reframing what a data analyst can do when letting these tools enable their work. For instance, generative AI can help produce more accurate and efficient analyses by automating repetitive tasks like data processing and exploratory data analysis.
This integration of generative AI into data analysts' and data scientists' roles can bring significant benefits. It can allow data analysts to take on more predictive and even prescriptive analytics tasks, working closer with their data science peers. It can enable data analysts to spend more time on human-centric problems. The data analyst can spend more time asking “why” instead of “what happened” and then continue up the pyramid to understand what happens next and what they should do about it.
How do I become an AI Data Analyst?
Integrating generative AI into an analyst’s workflow should be done judiciously. Are you aiming to enhance your productivity, or do you seek to develop a tool that your colleagues can use, potentially reducing the number of dashboard requests you handle? For those interested in AI assistants that improve workflow efficiency, consider exploring options like Tableau Pulse or Copilot on PowerBI.
If your goal is to provide non-technical users with tools that enable them to perform their analyses, thus reducing the number of data and dashboard requests that accumulate in your queue, you might want to explore a solution like Patterns.
Tools need a problem to solve, though. A data analyst should ask questions about their work to see where these tools fit best. Here are some examples:
What tasks can I automate using generative AI?
Where is human judgment needed in my workflow?
What insights can I improve on or check using generative AI?
How much time does generative AI save me? And what will I do with that time instead?
Where in my organization can I utilize generative AI to disseminate analyses?
What infrastructure is in place to support this? What data privacy considerations do I need to make?
Stanford stresses that to make the “human in the loop” concept work, these tools “should extend us.” Using these tools as an extension of a data analyst’s work will enable you to tackle those new and exciting problems, and enhance the work data analysts are already tasked with today. It should also guarantee that the AI data analysts of the future can reap the benefits of generative AI without worrying about replacement.
Analytics in natural language
What is an AI data analyst?
Explore how generative AI is reshaping analytics, intriguing professionals with its potential while signaling automation's impact on data analysis roles.
Chris Stanley
·
April 22, 2024
With the emergence of generative AI, analytics professionals have met the technology with intrigue and unease. It has forced a paradigm shift in what data analysts do. Curious data analysts are leveraging these tools to augment their work, while others may be seeing the writing on the wall, and to them, it reads “automate and replace.”
The concept of an “AI data analyst” has emerged to address both cases. For the former, the title has been used to describe data analysts who “combine traditional data analyst skills with expertise in AI and machine learning.” For the latter, it’s been used to describe the machine that replaces this role.
The future of data analysts might be somewhere in the middle. As this technology matures, so do its use cases. And it's those use cases that will shape what analytics looks like in the years to come.
An Etymology of the Four Types of Analytics
To understand how generative AI impacts data analysts and where this may be going, we must understand what analytics looks like today and where these roles currently operate.
Most analytics professionals work within four types of analytics: descriptive, diagnostic, predictive, and prescriptive. We can think of them as a pyramid built on top of one another, even though the roles and the types of analyses done within each layer can influence and impact another:
The most basic but foundational type of analytics is descriptive analytics. Harvard Business School describes descriptive analytics as “the process of using current and historical data to identify trends.” Descriptive analytics answers the question “what happened?” through analyses like looking at medians and means or charting data over time to see trends.
Diagnostic analytics is built on top of descriptive analytics. This type of analysis asks why something happened. Common techniques include hypothesis testing or looking at correlation and basic regression to help understand what’s driving a given result.
We do so much more with analytics today, and the significant difference between a data analyst and a data scientist comes when we jump from diagnostic to predictive analytics. IBM describes predictive analytics as the ability “to make predictions about future outcomes using historical data combined with statistical modeling, data mining techniques, and machine learning.” This builds on what we know from descriptive analyses and why we think it’s happening via diagnostic analyses to inform models like classification or clustering to anticipate what comes next.
Prescriptive analytics is the newest type to emerge and, as a result, is the hardest to define. Davide Frazzetto, Thomas Dyhre Nielsen, Torben Bach Pedersen, and Laurynas Siksnys, in their paper “Prescriptive Analytics: A Survey of Emerging Trends and Technologies,” describe prescriptive analytics as what “fills the gap between data and decisions.” They point to how prescriptive analytics takes the work from predictive analytics and uses those models to make decisions. That then is fed back to predictive analytics to reinforce models and decision-making. A good example of prescriptive analytics is how Google Maps takes in traffic data to help plan routes.
Where did Data Analysts and Data Scientists Come From?
Data analysts have worked in descriptive and diagnostic analytics for as long as computation has existed. Most of the work in these two spaces is based on foundational statistical concepts like mean, median, standard deviation, and the like. These concepts were sufficient for the amount of data we were collecting back then.
Then came “big data” and the data scientists trained to study it.
While Google trends indicated a rise in big data in the 2010s, the concept of big data came much earlier. In the late 1990s, computer scientists like John Mashey were looking to describe what they saw emerging in Silicon Valley: the different waves of more data sources, cheaper storage, and better computational power all cresting at once. Descriptive and diagnostic analytics could start to make sense of this new ocean of data, but we would need better techniques to understand the “why” and to move into predictive techniques.
The field of data science was almost exclusively academic at this point. Many credit Peter Naur for creating the term in 1974, when he started to draw the lines between data as a concept and what fields we would need to understand it better. Back then, prediction wasn’t even part of it. Data science and the idea of a data scientist didn’t take off until the 2010s when that big data wave was inundating most industries.
For the most part, data scientists tended to pick up where data analysts left off. Predictive techniques like regression models, decision trees, and neural networks require the foundation of descriptive and diagnostic analytics to predict.
As data science matured, the concept of prescriptive analytics started to emerge. Atanu Basu described the concept in 2019 as “practical and timely action plans to take advantage of the predictions” coming out of these models. It was natural for data science to take this branch of analytics.
The lines started to become clear: data analysts’ domain was in descriptive and diagnostic analytics, and data scientists would focus on making predictive and prescriptive models. This became the structure of a typical analytical organization.
“Human in the Loop” Instead of AI-First
Then came generative AI to blur those lines. And it didn’t take long.
It seemed like overnight tools like ChatGPT and Copilot became essential working companions. They continue to be force multipliers in the workplace, no matter the field or the role.
It is also natural for a data analyst to assume that generative AI is coming for jobs. Generative AI can be trained on internal data and documents, allowing it to do a decent chunk of diagnostic analytics. It already performs well with descriptive data if the datasets are processed cleanly. No wonder students in the field ask if they’ve chosen an “obsolete” career path, anticipating a future where AI data analysts are embedded in organizations instead.
Data scientists are not off the hook, either. While their domain transitions nicely to training and maintaining these large language models, much of the work needed to maintain these models occur in earlier analytical stages like predictive and prescriptive analytics.
So, what does a data analyst do? Should they simply concede to the future of automation? Find another job? Before hitting the panic button, we should recognize that this problem is not new. People are already thinking about structural shifts in how we can integrate generative AI without automating our jobs.
One of the concepts at the forefront of this human versus AI problem is the idea of a “human in the loop.” This concept emphasizes the importance of human expertise and judgment in the AI-driven analytics process. Stanford University’s Institute for Human-Centered AI frames this idea around a simple question: “How do we incorporate useful, meaningful human interaction into the system?”
For a data analyst with that panic button half-pressed already, it’s going to take a process of reframing what a data analyst can do when letting these tools enable their work. For instance, generative AI can help produce more accurate and efficient analyses by automating repetitive tasks like data processing and exploratory data analysis.
This integration of generative AI into data analysts' and data scientists' roles can bring significant benefits. It can allow data analysts to take on more predictive and even prescriptive analytics tasks, working closer with their data science peers. It can enable data analysts to spend more time on human-centric problems. The data analyst can spend more time asking “why” instead of “what happened” and then continue up the pyramid to understand what happens next and what they should do about it.
How do I become an AI Data Analyst?
Integrating generative AI into an analyst’s workflow should be done judiciously. Are you aiming to enhance your productivity, or do you seek to develop a tool that your colleagues can use, potentially reducing the number of dashboard requests you handle? For those interested in AI assistants that improve workflow efficiency, consider exploring options like Tableau Pulse or Copilot on PowerBI.
If your goal is to provide non-technical users with tools that enable them to perform their analyses, thus reducing the number of data and dashboard requests that accumulate in your queue, you might want to explore a solution like Patterns.
Tools need a problem to solve, though. A data analyst should ask questions about their work to see where these tools fit best. Here are some examples:
What tasks can I automate using generative AI?
Where is human judgment needed in my workflow?
What insights can I improve on or check using generative AI?
How much time does generative AI save me? And what will I do with that time instead?
Where in my organization can I utilize generative AI to disseminate analyses?
What infrastructure is in place to support this? What data privacy considerations do I need to make?
Stanford stresses that to make the “human in the loop” concept work, these tools “should extend us.” Using these tools as an extension of a data analyst’s work will enable you to tackle those new and exciting problems, and enhance the work data analysts are already tasked with today. It should also guarantee that the AI data analysts of the future can reap the benefits of generative AI without worrying about replacement.